Using the NCSA NT SuperCluster
DRAFT, v1.1, Sept. 1998
robp@ncsa.uiuc.edu
Overall architecture:
Remote access from desktop Windows machines
Can be any UNIX or Windows system with a Java 1.1 enabled browser
Cannot be accessed directly by users, only through the queuing system
Accounts and Passwords
NTSC Mailing List and Systems News
An online news directory will be created for users to be able track changes and updates to the system and a mailing list is being created to provide a single point of contact with the system administrators.
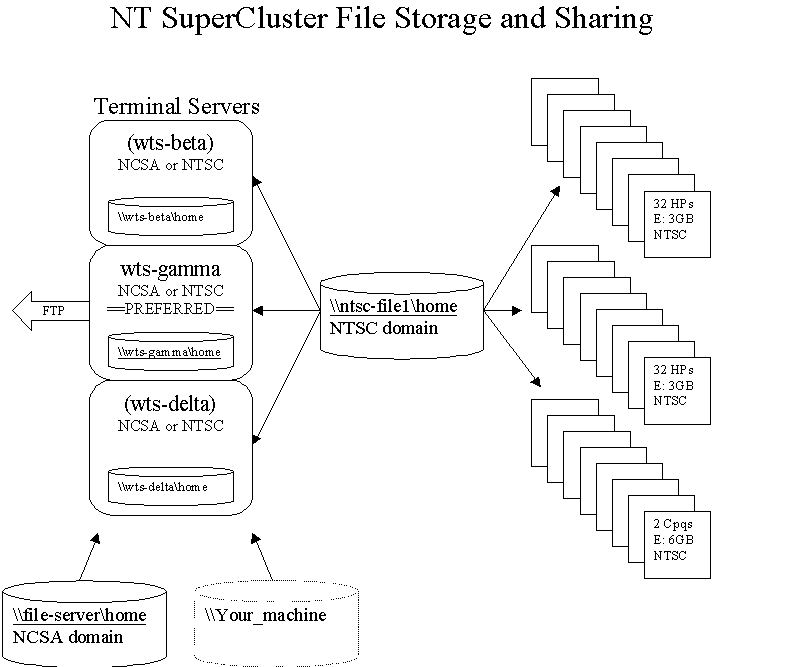
Front-ends, Terminal Servers and Fileservers
Microsoft Windows Terminal Server (WTS) is the name of the software package that you will use to access the application development environment on the cluster front-end machines. The "HPVM front-end" is the software that you will be using to submit jobs to LSF on the cluster from a browser.
You will have to install terminal server client from
\\wts-gamma\client onto a Windows 95 or NT machine before starting to use the cluster. Map this as a network drive to your machine and then run Setup from this directory. You should click on "Setup will install all components".MS Terminal Server should be installed on the Start bar. Click on "Client Connection Manager". When this comes up, click on File->New. Enter a description of the new connection, such as NTSC gamma, and the server namer: wts-gamma.ncsa.uiuc.edu. You can then enter your Useraname, Password and Domain to let it automatically log you in to the NCSA or NTSC domains or leave these blank which will allow you to choose on each connection who to login as. In the next dialog box, the screen size we are using is usually 800x600 or 1024x768. If you are using a modem, check the "Low Speed Connection" box. On the next screen, choose Desktop. Use the default Program Group in the next dialog box, followed by "Finish" in the last box. This should create an icon labelled NTSC gamma in the Client Connection Manager Window. You can change the options later by choosing Properties for NTSC gamma. Clicking on NTSC gamma will open a connection to wts-gamma that you can use to log in to the development machine.
Filesystems
The NCSA home directory will be on Z: for most users. This will be your default directory when you log in to the front-ends. This is part of the NCSA NT domain and is backed up for you by NCSA.
There can be local "home" directories created on the front end machines, i.e.
\\wts-gamma\home\username. If it does not already exist you can create this directory and use it for the development cycle. It is on a local disk for wts-gamma and will provide better performance than using the NCSA file-server. It is in the NTSC domain and is not backed up.When you use the batch system, your executable and input files have to be on ntsc-file1 and your output files will be on ntsc-file1. The cluster fileserver, ntsc-file1, needs to have a directory for your batch jobs,
\\ntsc-file1\home\username. This is another directory that you may have to create yourself. It is in the NTSC domain and is not backed up.The diagram gives an idea of the current layout of the filesystems and the sharing among the machines. They are tagged with either NCSA or NTSC to let you know which password you will have to use to be able to access them.
Compilers on the front-ends for users
At this time wts-gamma is the development front-end machine to use. It supports Digital Fortran and Microsoft C/C++ and has the MS Development environment installed. This has the online documentation for using both of these compilers.
To invoke these from the command line interface (cmd or bash)
Digital Fortran == df,
Microsoft C/C++ == cl
Development Environment == msdev
For compiler command line options, give the compiler /? on the command line. Note that compiler options under NT are designated with a forward slash (/) rather than a minus sign (-) as under UNIX.
Development environments
There are two environments that you can use on the front-ends to do software development. If you are used to using UNIX, you can invoke a bash shell that will provide many of the tools that you are used to using (make, tar, rudimentary vi, ar, ranlib, etc.). This is the Cygwin32 environment that is available from
www.cygnus.com. The gcc compiler does come with this environment but is not usable with the HPVM libraries for the cluster. The MKS toolkit which provides similar UNIX-like functionality and a Korn shell will be deployed on one of the front-ends. Tcsh and emacs are installed and available. The Microsoft Development environment is also available on the front-ends. To invoke either of these (Cygnus or MSDEV) from a cmd window:Microsoft Visual Development Environment == msdev
Cygwin32 Cygnus tools for UNIX bash shell == cygnus
MPI Libraries, include Files
The HPVM libraries that you will need to link with your MPI executable are (in order) mpi.lib, fm.lib, and myrilib.lib and are in D:\apps\hpvm\Myrinet\lib\ .
The include files are in d:\apps\hpvm\Myrinet\include. If you are using the Fortran versions, you may need to comment out the last line (if it isn't already):
C EXTERNAL MPI_NULL_COPY_FN, …..
Compilation and Makefiles
This is a simple example batch (.bat) script to compile an MPI program using Digial Visual Fortran for the cluster. The MS C/C++ compiler is similar.
df mpias_calc_r4.f mpias_comm_r4.f /LINK "d:\apps\hpvm\myrinet\lib\mpi.lib d:\apps\hpvm\myrinet\lib\FM.lib d:\apps\hpvm\myrinet\lib\myrilib.lib" wsock32.lib advapi32.lib dfport.lib /nodefaultlib:libcd.lib
This was invoked from the bash shell which made it necessary to double quote the paths to the MPI libraries to maintain the backslashes in the pathnames. If you were doing it from a MS cmd window, the backslashes would not have to be quoted. The dfport lib provides some portability routines for Fortran (clock, ctime and such). See the online docs in msdev for more information (search on dfport).
Some of the more useful compiler options are:
df /compile_only mpias_calc_r4.f or df -c mpias_calc_r4.f
to produce mpias_calc_r4.obj. The extension on the Fortran source file is assumed to be .f or .for. This can be changed to xyz with /extfor:xyz. The object files under these compilers will produce .obj files (rather than .o files as under UNIX) so it may be necessary to modify the Makefile to handle .obj rather than .o files. An alternative is to specify the output filename to get the .o extension:
df /compile_only /object:mpias_calc_r4.o mpias_calc_r4.f
The linker can be invoked separately by specifying the /link option to df.
The GNU gmake is available under the bash shell and it is invoked as "make".
If you want to use the Microsoft nmake command in a cmd window, you can see an nmake file example in d:\apps\hpvm\Myrinet\examples\Mpi\Makefile
Submission through LSF
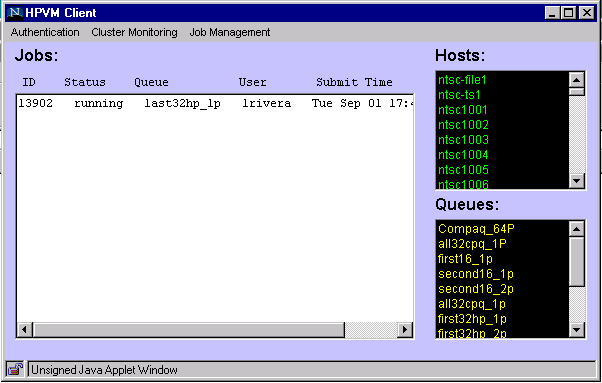
To submit a jobs to the NTSC through LSF, you will have to start the HPVM front-end. This is a software interface to LSF that will allow you to submit jobs from any Java 1.1 enabled browser.
IE 4 is already enabled to use Java 1.1. For Netscape, you will need to have 4.0 with the JDK 1.1 download from the Netscape Smart Update site. With a Java 1.1 enabled browser, go to:
http://ntsc-file1 and then "Click here to launch the HPVM client". This will start the HPVM front-end. To use it:Authentication->LogOn with your NTSC account name and password. You must *click* on Okay to get this accepted as just hitting Enter won't do the job.
Authentication->Console Log to watch the log to be sure your job was submitted successfully.
Job Management -> Submit Job to submit a job to the cluster. This will bring up a window that asks for the command line, the output filename, number of processors and queue.
Job Management -> Kill Job does not work correctly yet. The job will disappear from the queues but the processes will still be running on the compute nodes. More on this later.
Cluster Monitoring->Realtime Cluster Monitor to watch the activity of the machines. You can give this the Job ID for your job and monitor the CPU load, etc. Note: the scroll bars on the monitor do not work with Netscape but do work with IE 4. This display is updated every 15 seconds so it is only roughly real time.
Note: You will not be able to open and look at the output file that is being created by your application on ntsc-file1 while it is running
Job Start Up and Turnaround Time
Your job will appear in the queues as "pending" within about 15 seconds. If the resources are available, it will go to "running" status. It can still take awhile for LSF to start the processes on the machines. A job that uses a small number of processors, ~2-8, should show activity on the nodes within ~30 seconds of the job being reported as running. On the other hand, a 128 processor run can take 10-15 minutes to begin actually running. This is a known problem.
Monitoring the Cluster Activity
You can monitor the overall activity on the cluster with the GL monitor program that is accessible from ntsc-file1. You can run this on your windows machine by choosing Start->run and then entering \\ntsc-file1\glmon\glmon.
This is a graphical display that shows the machine names and the levels of activity as a 2D bar graph. Any machines reported in red are down.
Killing a Job on the Cluster
I/O redirection
You can use I/O direction on the cluster to send an input file into your executable and collect the output into a disk file to be looked at after the job completes. The most important note is that you cannot simple use > or < to do the redirection. There are a couple of things to be aware of:
Input files
Output files
The working directory for your job
The executable must reside on \\ntsc-file1. There is space on this machine for you to make a working directory. The directories are not backed up at all. Anything on
\\ntsc-file1 is considered to be volatile.If you specify a full UNC pathname for the executable, this will determine the working directory and it will be prepended (if necessary) to the path for the input file(s) and the output file. For example, the input line for a job submission might look like:
Command line:
\\ntsc-file1\home\userT\lab\run_reduce reduce_input -np 4 -key rand8Output filename: reduce_output
The file reduce_input will be expected to be in the directory
\\ntsc-file1\home\userT\lab.
On the other hand, running something like:
Command line: hostname
Output filename: output_file
This will result in your output file either not appearing at all or appearing in some unexpected place.
Moving files to \\ntsc-file1:
You can move your executable and input files to
\\ntsc-file1 by mapping it as a network drive to the front-end that you are using or to a Windows machine on your desktop or by using ftp to a UNIX machine. Note: you cannot use ftp from within the bash shell because carriage return/line feed is supplied for you. If you do invoke ftp, it will just "skip over" your username and ask for your password and fail.Scratch space on the cluster machines:
There is a ~3 GB scratch area on each of the machines as E: that is available for you to use while you have an application running on the machine. Please clear this off when your job finishes as we do not yet have a wiper in place.
Security
The level of security on the NT SuperCluster will be increasing as time passes and the system matures. At this stage, you should be very cautions about putting sensitive data or code on the disks in the NTSC domain.
Additional information and documentation:
HPVM documentation on wts-gamma is in d:\apps\hpvm\doc
MPI examples that come with HPVM are in d:\apps\hpvm\Myrinet\examples\Mpi
{kind=link}
{kind=link}