Artificial intelligence, machine learning and deep learning have been tech buzzwords for a while now. But what do they mean? And just how does a machine learn, especially a supercomputer performing quadrillions of calculations a second?
Scientists in NCSA’s Center for Artificial Intelligence Innovation (CAII) tackle these problems every day. Artificial intelligence (AI) refers to the wide-ranging branch of computer science concerned with building machines capable of performing tasks that typically require human intelligence. So machine learning and deep learning (DL) are forms of AI.
In machine learning, algorithms incorporate the data given to it and get progressively better over time. Think of an Alexa that learns your voice and phrasing so that it can understand the commands you give it. On the other hand, deep learning has layered structured algorithms that can learn and make intelligent decisions on its own, similar to how a human brain would draw conclusions.
While DL has emerged as a powerful tool to solve a variety of complex problems that have been difficult to solve with traditional methods, domain experts attempting to apply DL methodology often have to learn to code in complex languages in order to use it.
But CAII, along with NCSA’s Innovative Systems Laboratory (ISL), has been exploring new DL tools that make implementing DL models easier. NCSA researchers Shirui Luo and Volodymyr Kindratenko became especially interested in IBM Visual Insights (formerly IBM PowerAI Vision) and Google’s AutoML Vision. These provide a web-based graphical user interface for configuring and training a variety of models, as well as tools and APIs for deployment on a variety of platforms.
Tools, such as IBM Visual Insights, lower the entry barrier for domain scientists to use otherwise very complex DL models. Researchers are no longer concerned with the implementation details, performance tuning, data input, and a myriad of other tasks and issues the model developers are preoccupied with. Instead, they are concerned with how to make best use of the state-of-the-art DL models to solve their exact problem.
Volodymyr Kindratenko, NCSA Senior Research Scientist, CAII Co-Director
Both IBM Visual Insights and Google AutoML Vision implement complex workflows that connect many services and computational resources to deliver complex functionality that, until recently, required a substantial coding effort. Since Google’s AutoML Vision’s applicability to medical problems was discussed in a paper published by Livia Faes and her colleagues in The Lancet in September 2019, Luo and Kindratenko focused on applying IBM Visual Insights to COVID-19 research challenges. That work was published in Computing in Science & Engineering and recently republished in Computing Edge.
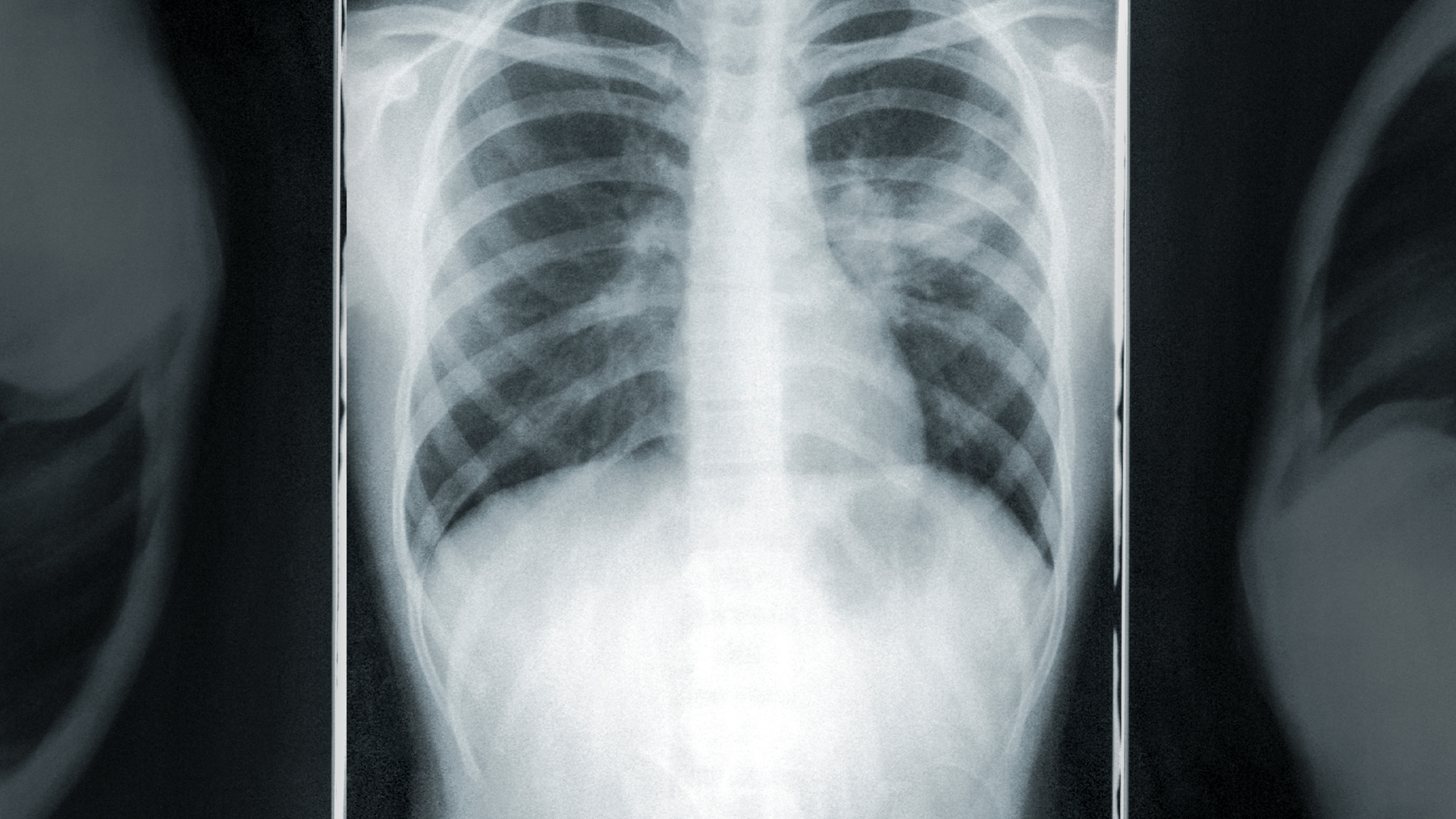
TRAINING USING COVID-19 CHEST X-RAYS
As the COVID-19 pandemic developed, researchers around the world focused on what they could do to help mitigate it. The CAII team explored how they could use AI to make a difference in medical diagnoses. Models existed to identify pneumonia in chest x-rays, but they often involved advanced algorithms that made them difficult for those with limited coding skills.
Luo and Kindratenko uploaded an annotated data set of chest x-rays from Github into IBM Visual Insights instance deployed at ISL which allowed them to streamline processes for image labeling, model training, and model deployment. They also trained a DL model with only a few clicks since the Visual Insights platform offers built-in models that are already pre-trained as a starting point. Once their model was trained, it is easily deployable through a variety of tools, including REST APIs (a way for two computer systems to communicate in a way similar to web browsers and servers) and even a mobile application.
“The IBM Visual Insights provides a web-based graphical user interface, or GUI, for configuring and training a variety of models, which empowers domain experts without any knowledge of coding or underlying HPC hardware to easily take advantage of complex DL models trained on their large datasets. We demonstrated an x-ray image classification example to show how the IBM Visual Insights helps train DL models. The platform uploaded/labeled datasets, performed data augmentation, model training and validation, and visualization with only a few clicks using the streamlined GUI interface,” says Luo.
DRAWBACKS
DL tools aren’t perfect. For example, models used by IBM Visual Insights have limitations on the size and resolution of images (1-2 megapixels). High-resolution images need to be divided into smaller sub-images if they require fine details or downsampled if they have coherent structural information that cannot be divided. The images are automatically scaled to the appropriate dimensions for the model to use during the training phase.
And Luo and Kindratenko note that the functionality of DL tools is still limited to just a few prearranged models that work well only for specific problems. The users are also restricted to tweaking only some model parameters while leaving the majority of the decisions to the computer.
But these tools provide access to complex DL models and empower domain scientists to take advantage of this new methodology, an important first step.
“The wide-spread adoption of AI hinges on the availability of such tools and the ease of use they provide. Current limitations are an artifact of the models that have been developed,” notes Kindratenko. “As these models continue to mature and their requirements continue to evolve, the tools follow and become more robust and more versatile. These tools and pre-trained models are also becoming readily available for use in the form of AI as a service (AIaaS) on clouds, empowering the research community to tap into AI capabilities with ease.”
ABOUT NCSA
The National Center for Supercomputing Applications at the University of Illinois Urbana-Champaign provides supercomputing and advanced digital resources for the nation’s science enterprise. At NCSA, University of Illinois faculty, staff, students and collaborators from around the globe use these resources to address research challenges for the benefit of science and society. NCSA has been advancing many of the world’s industry giants for over 35 years by bringing industry, researchers and students together to solve grand challenges at rapid speed and scale.