

You may have read about how artificial intelligence applications like ChatGPT were trained by ingesting as much freely available data on the internet as possible. It’s no secret that this has caused significant concern in research circles about how unfiltered data can affect AI-generated answers. But accuracy isn’t the only concern when it comes to training AI on “all the data.” The amount of resources it takes to ingest so much data to build the large language model (LLM) that forms the “brain” of one of these chatbots is enormous. Researchers who wish to explore LLMs, test and refine training algorithms or create project-specific chatbots for domain-specific research usually don’t have the same resources as companies like OpenAI or Google. These are exactly the types of issues that researchers at the University of Illinois Urbana-Champaign (U. of I.) are trying to resolve.
Ishika Agarwal, a doctoral candidate at U. of I., is part of a team of researchers who used NCSA resources to create a new framework for training AI called DELIFT (Data Efficient Language model Instruction Fine-Tuning). Last year, they presented their work on DELIFT at the International Conference on Learning Representations (ICLR) in Singapore. They used NCSA’s Delta supercomputer to help test the DELIFT framework.
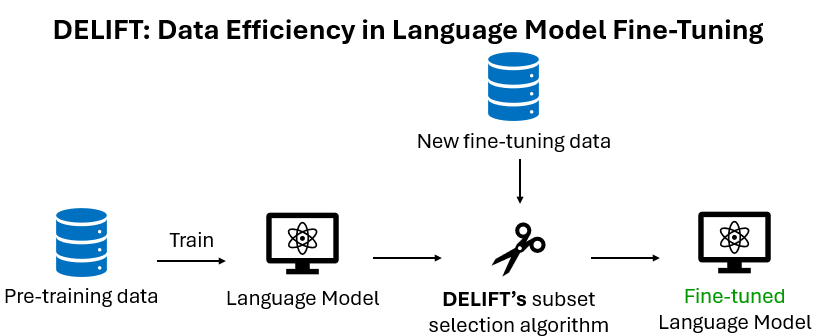
DELIFT is designed to train AI more efficiently – meaning faster and cheaper – by being “smarter” about what data is used in the training process. “DELIFT tries to reduce the amount of data that we use to train large language models because training is computationally intensive,” explained Agarwal. “ It calculates the interactions between data points in a dataset to ensure that there aren’t redundant, noisy or conflicting samples. All this ensures that your dataset is the smallest and most informative to train your model on.”
One problem with training AI by giving it a bunch of data is that data doesn’t exist in a vacuum. There’s a lot of context around specific pieces of information. For instance, much of the data on the internet is redundant, and using it all to train an LLM is a waste of resources. Let’s say you want to train an LLM to understand that 1+1=2. At some point, the LLM no longer needs examples to learn the answer, even though there are likely millions of pages online that say that 1+1=2.
Some data also needs to be “unlocked” before other data can be understood. Simple math eventually builds to complex math, and in order for an LLM to understand complex physics equations, it would need to be trained on the simple stuff first.
“Understanding the dynamics of data is difficult because data can interact with each other in many ways,” said Agarwal. “DELIFT provides an intuitive way to understand and measure the dynamics of your data for various fine-tuning tasks.”
DELIFT is designed to train LLMs much more efficiently, ensuring that the data used to train an LLM is necessary and of high quality. Think of what DELIFT does as similar to getting a hint to solve a brain teaser – the hint could help you connect the dots to the answer. DELIFT does something similar by testing “samples” of data to see if they help the model solve other problems. As a result, DELIFT will occasionally outperform models that use 100% of a dataset.
“More data is not always good because data has to be high quality. If we train our language model on garbage, it’s only going to output garbage,” said Agarwal. “That’s why we see data selection methods often outperforming models that are trained on 100% of data. In data, ‘noise’ can refer to bad quality samples (mis-labeled, improper formatting, confusing characters, wrong answers, etc.), and ‘redundancy’ refers to duplicated samples that contain the same information (a model does not need to see both samples to learn the information).”
Being able to rely on your school’s resources allows you to have research flexibility to work on any cool idea you have, and provides a great sense of relief that you have resources to carry out the projects you want to be a part of.
University of Illinois Urbana-Champaign
A defining aspect of research at institutions like U. of I. and NCSA is that these places strive to make the most of the limited resources required to run projects that use machines like Delta. Finding more efficient, less resource-intensive ways to produce the kinds of important research achievements the university is known for is just one of the many goals at NCSA. The fact that the Center supports the research Agarwal’s team is engaged in is just one example of how those intentions play out – DELIFT is specifically designed to do more with less.
“Data collection is an expensive task, time and money-wise, because it can involve human verification to make sure the data is of good quality,” said Agarwal. “But with DELIFT, we can prune out a lot of samples and ensure that we annotate samples that are informative. Furthermore, training on fewer data allows you to train models faster and with fewer resources.”
Needing fewer resources means that researchers who often work in resource-constrained environments can use a framework like DELIFT to scale down the requirements for their projects.
“I’m sure there are lots of use cases where folks want to train models for a very specific task, but aren’t able to do so because of resources,” said Agarwal. “DELIFT can try to alleviate some costs because it not only creates a smaller dataset, but it also creates a dataset that is targeted for a particular language model. If we know a language model has certain weaknesses, DELIFT will find those weaknesses and keep data that can ameliorate those weaknesses. So the dataset is both smaller and curated for your particular model.”
While DELIFT can help with projects with smaller datasets in mind, the question remains whether the same type of framework could help lower resource costs and improve the quality of results when applied to some of the world’s largest AI models.
“That’s actually a big research question!” said Agarwal. “We are currently looking into ways we can approximate the interactions between datasets, instead of directly computing it, to avoid the quadratic cost.”
I used Delta GPUs to help me run the experiments for my paper. It was really easy to use and required minimal setup, which helped me get results fast.
University of Illinois Urbana-Champaign
As Agarwal’s team continues to work on these bigger questions, they are also working on new approaches to improve LLM training. They will continue to use NCSA resources as they tackle their next research question related to these same LLM issues.
“We’re working with NCSA to understand how to measure a model’s weaknesses, a sort of precursor to DELIFT,” said Agarwal. “To scope down the problem, we study the model’s weaknesses through a multilingual perspective. We find that models answer questions differently when prompted in different languages (English versus Hindi versus Spanish, etc.). Our preprint shows this phenomenon and finds ways to mitigate it. But we are currently working, using ACCESS resources, on measuring why this happens and where this comes from.”
Agarwal and her team used the U.S. National Science Foundation ACCESS program to get an allocation (CIS240550) on NCSA’s Delta supercomputer for work on the DELIFT framework. Their team is using allocation CIS260246 for their work on LLM language-specific knowledge.
ABOUT DELTA AND DELTAAI
NCSA’s Delta and DeltaAI are part of the national cyberinfrastructure ecosystem through the U.S. National Science FoundationACCESS program. Delta (OAC 2005572) is a powerful computing and data-analysis resource combining next-generation processor architectures and NVIDIA graphics processors with forward-looking user interfaces and file systems. The Delta project partners with the Science Gateways Community Institute to empower broad communities of researchers to easily access Delta and with the University of Illinois Division of Disability Resources & Educational Services and the School of Information Sciences to explore and reduce barriers to access. DeltaAI (OAC 2320345) maximizes the output of artificial intelligence and machine learning (AI/ML) research. Tripling NCSA’s AI-focused computing capacity and greatly expanding the capacity available within ACCESS, DeltaAI enables researchers to address the world’s most challenging problems by accelerating complex AI/ML and high-performance computing applications running terabytes of data. Additional funding for DeltaAI comes from the State of Illinois.