
This article, written by John Russell, originally appeared in HPCwire and is republished with permission.
If you work in scientific computing, MPI (message passing interface) is likely a part of your life. It may be hidden underneath the applications you run or you may wrangle with it yourself to drive parallel compute efforts. Few people know MPI better than Bill Gropp, the director of the National Center for Supercomputing Applications and one of a dedicated cadre of early developers who created MPI.
It’s been 29 years since the first MPI version was released and the manual has grown to more than 1,000 pages. In a fast-paced, substantive talk yesterday as part of Dell Technologies HPC Community events (this one online), Gropp reviewed MPI’s roots, heyday, and dug into how MPI needs to evolve to catch up with modern heterogeneous architecture.

“The thing to remember is that before MPI, which is now 29 years old, there was really chaos. There were a lot of different systems for programming these distributed-memory parallel machines,” said Gropp. “They had similar names for similar functions, but they weren’t identical. They even had somewhat different semantics. And this was happening about the same time as essentially the microprocessor took over – the famous Attack of the Killer Micros.”
“It was also an important time because it was when Moore’s law and Dennard scaling, which is what actually drove the increases in performance, happened. That gave a tremendous amount of architectural stability. So systems got faster, every 18 months, the usual sort of doubling, [and] you didn’t have to do very much. The advances in the semiconductor technology just sort of gave you that for free. That provided both stable hardware and software environments even though quantitatively the speeds increased exponentially, pretty much once you wrote a code, it would continue to just run faster,” he recalled.
Not so much today. The rise of heterogeneous architecture and the death/slowdown of Moore’s law have changed the game. Presented here are a handful of Gropp’s slides and comments (lightly edited) but his brief (~35ish) minute presentation is well worth a watch. (link to video)


Dealing with New Challenges
“What we’ve seen since the end of Dennard scaling, which was ~2005-2006 depending on you look at it, [is that] to continue to get performance we’ve had to do innovation in the architecture and that innovation has gone in a number of different directions. It’s led to much more complex node designs. So I put up a couple [slides] here (see below). The key here is that a lot of the particularly high-end nodes take advantage of GPUs. But even when they don’t – you could argue that Fugaku nodes don’t use GPUs but they have very powerful, specialized vector extensions. So while it’s integrated into this same processor, it’s actually still a separate way of getting performance. We even see that on the regular CPU nodes. If you look at applications, a lot of applications struggle to take advantage of even the existing vector instructions,” said Gropp.
“One of the things that I’ve heard people say is that well, people didn’t really expect the nodes to go in a direction like this,” said Gropp. “That’s really not true. I was part of a study that was conducted around 2012, for NASA, looking at computational fluid dynamics and 2030. And here are predictions that we made. It was published in 2014. I won’t go through these in detail, but if you look at it (slide below), it’s actually not too far off of where we ended up being, particularly if you generalize that processor to include the GPU. I will say what did we miss is, along with a lot of people, we were expecting tighter integration. In fact, what we were expecting was a much tighter integration, something that looked more like a Fugaku node than the kinds of nodes that we get. Still this is really pretty close to where we are in 2023.”


MPI’s Simplicity and Completeness
There’s no arguing with MPI’s success throughout HPC. Gropp weighed in on why that is the case.
“Why MPI was successful? I think it’s important to recognize that it simultaneously addresses a number of issues. Phase one was portability, but also the performance, simplicity and symmetry. The initial MPI wasn’t a huge number of functions, but it was also a fairly complete set. So why is that important? That means as you’re developing your application, you don’t suddenly run into a place where you have to change to a different approach because you’ve run out of the piece that you need. The modularity, composability and completeness, those were important because they helped enable the development of software libraries built on top of MPI,” said Gropp.
“Let me focus just a little bit on the performance versus productivity. This is an issue that is often brought up as a challenging problem with MPI. MPI really gives you those tools for achieving performance. In large part, it does that by not getting in the way of locality management, managing where memory is, how you access it, and so forth. But that’s exactly the thing that makes MPI, in some ways, difficult to program,” he noted.

“What we found is that, while it’s a problem and can be a challenge from a productivity standpoint, to manage locality, the one thing that you can do to make it even harder is to try to hide that from the performance user and make it so that they don’t have any direct tools to manage locality. So that is, in fact, sort of simultaneously one of the weaknesses of MPI – you have to manage locality – but it’s a strength because it gives you the tools to manage it, which many other systems do not and depend on, effectively magic in the compiler and the runtime and so forth.”
While MPI proved enormously useful, it has clearly aged. The rise of POSIX for example has never been optimum for MPI. That said it is used in some surprising places.
Gropp noted, “I do want to mention that MPI is used in places beyond the sort of usual suspects of fluid dynamics or material science and so forth. So, there’s a nice blog posting from OpenAI about how they train their large language models. And I included this quote here (below) that says that their biggest jobs run MPI, interestingly enough, for people who followed some of the discussions about fault tolerance and MPI, they used a very classic HPC approach, which is a checkpoint restart. Now, whether that’s whether one could do better with a more fault tolerant approach is another discussion we could be having. But I did find this interesting that MPI is very successful in some of these really challenging large-scale new applications in AI.”

What Changes are Needed Now?
Gropp didn’t shy away from MPI future challenges.
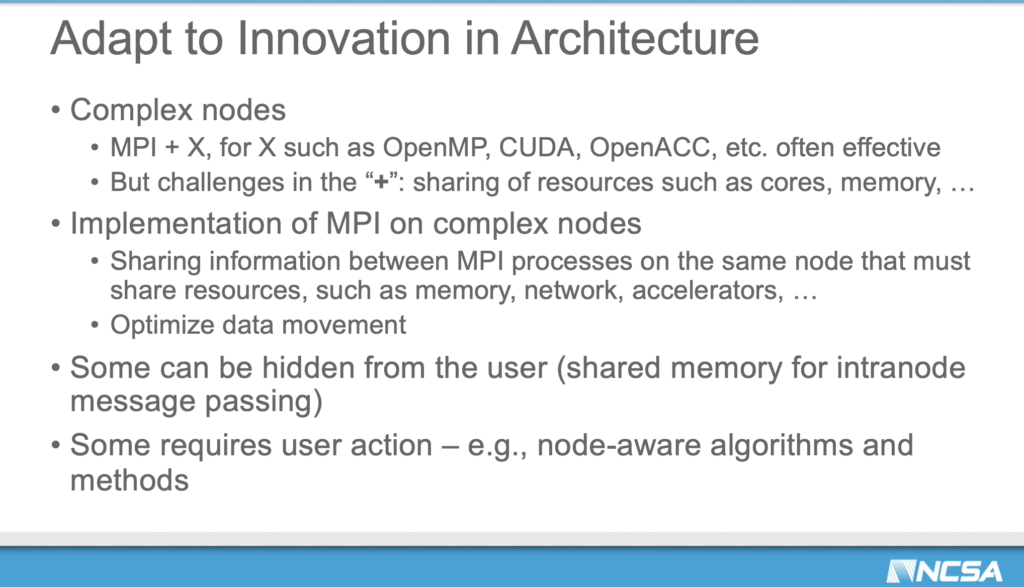
“I think there’s two broad categories of these. There are the intranode considerations. So, as I mentioned, the nodes are getting more and more complicated. We’re getting new memory architectures. SMPs are…with larger, larger numbers of cores, even with multiple coherence domains or possibly regions of increased performance. So, in NUMA zone inside of a processor, you’ve got the accelerators. It is possible – and I’ve argued for this in some cases – to use MPI… We still use an MPI everywhere model will take advantage of some features, but that is becoming increasingly sort of tortured. There are optimizations that are being missed, for example, if you do MPI everywhere, the MPI internals have to be duplicated. And that adds extra overhead, extra memory traffic, all things that can suck performance,” said Gropp.
“You’ve also got internode considerations, particularly as we get increasingly capable networks that can do various kinds of remote direct memory access. Also, more sophisticated operations, including remote atomics and message passing, and so forth. There are some interesting questions here about the some of the model that MPI provides for this. For example, there’s guarantees about ordering, which some applications don’t need and enforcing those, again, adds extra overhead, particularly latency. So, as we look at this sort of high and low level, we need to be thinking about how we deal with the change in the node architectures and the new kinds of memory systems, memory models that we have now. There was a time, initially, when MPI was defined, when some of us that are old enough will remember segmented memory architectures, and MPI was designed to support that.
“As I mentioned in answer to that earlier question, there is really an increasing need to do things to help the strong scaling case because that’s becoming a bottleneck for a lot of applications where you can’t just simply keep making the application larger so that you can keep your flop rates up; you’ve got to fixed problem size, and so forth. SMPs are also encouraging the use of threads on MPI performance and that area has been a challenge. Some of that is the semantics that seemed like a good idea at that time, but in fact, have impacts that you might not think, and there’s also new ideas in how we build these codes,” said Gropp.
“MPI really does need to adapt to this innovation in architectures,” continued Gropp. “One of the things that has succeeded and it was part of the initial design is MPI+X, where that X might be OpenMP, it might be OpenACC, it might be CUDA, it might be OneAPI, and so forth. We can hide some of this from the user, but some of this will require some work from the user.” Yes, that means algorithm change, said Gropp.


For such a brief talk, Gropp packed in a great deal of material (kudos to Dell for organizing the event). It’s worth a watch.
Link to Dell Technologies HPC Community events: https://dellhpc.org/events
Slides courtesy of Bill Gropp.
Gropp received his bachelor’s degree in Mathematics from Case Western Reserve University, a master’s in Physics from the University of Washington and completed his Ph.D. in Computer Science at Stanford University. He joined the University of Illinois in 2007 as the Paul and Cynthia Saylor Professor in the Department of Computer Science. From 2008 to 2014, he was the deputy director for research for the Institute of Advanced Computing Applications and Technologies at NCSA.
In 2011, Gropp became the founding director of the Parallel Computing Institute, a unit within the College of Engineering. In 2013, he was the first person to be selected for the Thomas M. Siebel Chair in Computer Science, a professorship position established by the famous Siebel Systems founder and UIUC alumnus. In 2016, he was appointed as acting director of NCSA, officially becoming director in 2017.
Gropp helped create the Message Passing Interface (MPI) and the Portable, Extensible Toolkit for Scientific Computation (PETSc) with the team receiving an R&D 100 Award in 2009 as well as another R&D 100 award for MPICH, a freely available, portable implementation of MPI.
Gropp is a Fellow of the American Association for the Advancement of Science (AAAS), the Association for Computing Machinery (ACM), the Institute of Electrical and Electronics Engineers (IEEE) and the Society for Industrial and Applied Mathematics (SIAM) as well as an elected member of the National Academy of Engineering. He was the 2022 President of the IEEE Computer Society, the largest society within IEEE. He is also a member of the Executive Committee of the Computing Community Consortium.
BONUS SLIDES


